
이번 포스팅에서는 JPA N+1 문제 해결 방법에 세 가지를 알아본다.
N+1 문제란?
N+1 문제는 한 번의 select 쿼리를 실행했을 때 N+1번의 select 쿼리가 실행되는 것을 의미한다.
N+1 문제를 강제로 발생시켜보자.
Member 클래스와, Team 클래스는 아래와 같다.
// Member.java
@Entity
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString(of = {"id", "username", "age"})
public class Member {
@Id @GeneratedValue
@Column(name = "member_id")
private Long id;
private String name;
private int age;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
public Member(String name, int age, Team team) {
this.name = name;
this.age = age;
this.team = team;
}
}// Team.java
@Entity
@Getter @Setter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@ToString(of = {"id", "name"})
public class Team {
@Id
@GeneratedValue
@Column(name = "team_id")
private Long id;
private String name;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
public Team(String name) {
this.name = name;
}
}
MemberTest 클래스는 아래와 같다.
// MemberTest.java
@SpringBootTest
@Transactional
public class MemberTest {
@PersistenceContext
private EntityManager em;
@BeforeEach
public void init() throws Exception {
Team teamA = new Team("teamA");
Team teamB = new Team("teamB");
em.persist(teamA);
em.persist(teamB);
Member member1 = new Member("member1", 10, teamA);
Member member2 = new Member("member2", 20, teamB);
em.persist(member1);
em.persist(member2);
em.flush(); // 강제로 DB insert 쿼리 실행
em.clear(); // 영속성 컨텍스트 캐시 제거(캐시를 제거하지 않으면 1차 캐싱으로 인해 다시 select 하지 않으므로)
}
@Test
@DisplayName("N + 1 문제 발생")
public void n_plus_1_issue() throws Exception {
List<Member> members = memberRepository.findAll();
// Team 데이터가 2개라 총 1 + 2 = 3번의 쿼리가 실행된다.
for (Member member : members) {
System.out.println("member = " + member);
System.out.println("-> member.team = " + member.getTeam());
}
}
}위 테스트 코드를 실행해보자.

Member 엔티티의 team 필드에 접근 시도를 할 때 Team 엔티티의 지연 로딩으로 인해 Team 객체 수만큼 select 쿼리가 실행되어 N+1 문제가 발생한 것을 확인할 수 있다.
빨간색은 member 조회이고 노란색은 team 조회이다. (1번의 쿼리 실행 -> N+1 문제 발생)
이번 예제에서는 Team 데이터가 2개뿐이라 2번만 조회됐지만, 만약 10만개라면 select를 10만번 했을 것이다.
이런 N+1 문제를 해결하기 위한 방법은 여러 가지가 있는데 한번 알아보자.
1. Fetch Join
첫 번째로 N+1 문제를 해결하는 방법은 Fetch Join 방식이 있다.
Fetch Join은 JPQL을 사용하여 조회 시 바로 가져오고 싶은 엔티티 필드를 지정하여 모든 데이터를 조회하는 방식이다.
Spring Data JPA에서는 @Query 어노테이션을 사용하면 된다.
MemberRepository를 하나 생성하고 findAllFetchJoin이라는 메서드를 생성했다.
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m join fetch m.team")
List<Member> findAllFetchJoin();
}
그리고 MemberTest.java에 테스트 메서드를 하나 생성했다.
@Test
@DisplayName("Fetch Join을 사용하여 N + 1 문제 해결")
public void solve_n_plus_1_issue_with_fetch_join_spring_data_jpa() throws Exception {
List<Member> members = memberRepository.findAllFetchJoin();
// Team 데이터가 2개여도 페치 조인을 사용했기 때문에 총 1번의 쿼리가 실행된다.
for (Member member : members) {
System.out.println("member = " + member);
System.out.println("-> member.team = " + member.getTeam());
}
}
위 테스트 메서드를 실행하면 한 번의 select 쿼리를 날려 모든 데이터를 조회하는 것을 확인할 수 있다.

2. Entity Graph
두 번째로 N+1 문제를 해결하는 방법은 Entity Graph 방식이 있다.
Entity Graph 방식은 Fetch Join을 하는 또 다른 방법이라고 생각하면 된다.
@EntityGraph 어노테이션을 사용하여 해결하는데 해당 어노테이션은 org.springframework.data.jpa.repository 패키지에 속하므로 Spring Data JPA에서만 사용이 가능하다.
public interface MemberRepository extends JpaRepository<Member, Long> {
@EntityGraph(attributePaths = {"team"})
@Query("select distinct m from Member m")
List<Member> findAllEntityGraph();
}@EntityGraph의 attributePaths에 쿼리 수행 시 바로 가져올 필드명을 지정하면 된다.

EntityGraph와 Fetch Join의 차이점이 존재한다.
EntityGraph는 데이터를 조회할 때 left join을 사용하지만, Fetch Join을 사용할 때 데이터를 조회하는 경우에는 inner join을 사용한다.
Fetch Join 방식은 페이징 처리 시 주의해서 사용해야 한다.
다대일 관계에서는 offset, limit 키워드를 사용하여 페이징 처리가 정상적으로 이루어지지만,
일대다 관계에서는 offset, limit 키워드를 사용하지 않아 페이징 처리가 되지 않는다.
다대일 관계에서의 Fetch Join을 활용한 페이징 처리
public interface MemberRepository extends JpaRepository<Member, Long> {
@EntityGraph(attributePaths = {"team"})
@Query("select distinct m from Member m")
Page<Member> findAllPage(Pageable pageable);
}@Test
@DisplayName("다대일: Fetch Join을 사용해도 페이징 처리 시 N + 1 문제가 발생하지 않는다.")
public void pagingFetchJoinTest() throws Exception {
Page<Member> memberPages = memberRepository.findAllPage(PageRequest.of(1, 2));
memberPages.forEach(member -> {
System.out.println("member = " + member);
System.out.println("-> member.team = " + member.getTeam());
});
}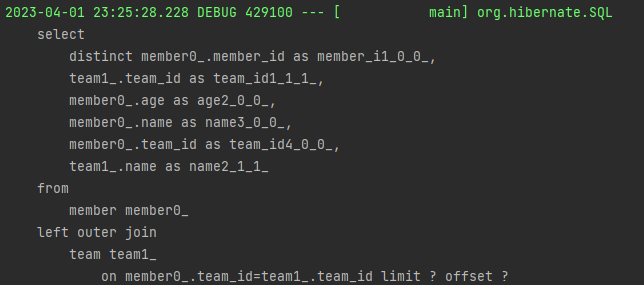
limit, offset 키워드를 사용하여 정상적으로 페이징 처리가 된다.
일대다 관계에서의 Fetch Join을 활용한 페이징 처리
public interface TeamRepository extends JpaRepository<Team, Long> {
@EntityGraph(attributePaths = {"members"})
@Query("select distinct t from Team t")
Page<Team> findAllPage(Pageable pageable);
}@Test
@DisplayName("일대다: Fetch Join을 사용하면 페이징 처리 시 N + 1 문제가 발생한다.")
public void pagingFetchJoinTest2() throws Exception {
Page<Team> pageTeams = teamRepository.findAllPage(PageRequest.of(0, 2));
pageTeams.forEach(team -> {
System.out.println("team = " + team);
System.out.println("-> team.members = " + team.getMembers());
});
}
다대일 관계와는 다르게 데이터를 조회할 때 offset, limit을 사용하지 않았다.
일대다 관계에서 Fetch Join을 이용한 페이징 처리를 시도 시 아래와 같은 경고를 띄워준다.
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!위 경고가 어떤 의미인지 검색해봤는데 DB로부터 페이징 처리가 된 데이터를 받는 것이 아니라 DB로부터 모든 데이터를 받아온 이후 메모리에서 페이징 처리를 해서 값을 준다는 의미이다.
즉, 일대다(@OneToMany)의 경우 페이징 처리 쿼리를 날려도 모든 데이터를 조회해서 애플리케이션 단에서 처리하니 아무 의미가 없다는 것이다.
이럴 때는 바로 아래에서 살펴볼 batch size 방식을 사용해서 해결할 수 있다.
3. Batch Size
fetch join을 사용할 때 일대다 연관관계에서는 페이징 처리가 이루어지지 않았다.
이럴 때는 @BatchSize 어노테이션을 사용하면 해결할 수 있다.
주의할 점은 @BatchSize를 사용하려면 fetch join을 아예 사용하지 않고 조회할 컬렉션 필드에 대해서 @BatchSize를 걸어 해결을 해야 한다는 점이다.
fetch join과 @BatchSize를 함께 사용하면 fetch join이 우선시 적용되어 @BatchSize가 무시되기 때문이다.
@BatchSize(size = 100)
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();위처럼 일대다 연관관계에 @BatchSize를 100으로 설정하고 테스트 아래의 테스트 코드를 실행해보자.
@Test
@DisplayName("일대다: @BatchSize를 사용하면 페이징 처리를 할 수 있다.")
public void pagingWithBatchSize() throws Exception {
// fetchJoin이 아닌 기본 findAll을 사용했습니다!!!!
Page<Team> pageTeams = teamRepository.findAll(PageRequest.of(0, 2));
pageTeams.forEach(team -> {
System.out.println("team = " + team);
System.out.println("-> team.members = " + team.getMembers());
});
}
기존의 지연로딩에 대해서는 객체를 조회할 때 그때그때 쿼리문을 날려서 N+1 문제가 발생한 반면 @BatchSize를 사용하면 객체를 조회하는 시점에 해당 in 절을 사용하여 batchSize만큼(여기서는 100개) 한번에 가져온다.
이는 뒤에 생길 지연 로딩을 미리 방지할 수 있다.
결론
다대일 관계에서는 Fetch Join을 사용해도 괜찮다.
일대다 관계에서는 Fetch Join 대신 @BatchSize 사용을 하는게 좋을 것 같다.